💡Our Hypothesis
Unlike Google's search results which provide clear, consistent rankings, we hypothesized that ChatGPT doesn't actually "rank" brands in the traditional sense. A brand might be mentioned first in one answer but appear later (or not at all) in others, suggesting that ChatGPT's responses are more about contextual relevance than strict ranking.
📚Inspiration: Elie Berreby's Analysis
This experiment was inspired by Elie Berreby's article "Rankings Don't Apply to AI Search", which argues that traditional SEO ranking concepts don't apply to AI-powered search. Berreby suggests that AI responses are inherently variable and context-dependent, challenging the notion of consistent rankings in AI-generated content.
Methodology
To test this hypothesis, we conducted a comprehensive experiment with 100 runs across four distinct rounds:
1Round 1 (Baseline)
100 runs with search mode disabled, using the exact same question to establish a baseline for ChatGPT's response patterns
2Round 2: Question Variations
100 runs with slight variations in question phrasing to test Elie Berreby's point about response consistency
2.2Round 2.2: Contextual Variations
100 runs with more significant question variations, focusing on different aspects like reliability, best taste, and quality to understand how context affects brand visibility
3Round 3: Search Mode Enabled
100 runs with search mode enabled to analyze how web search capabilities impact response variability
Key Findings
Round 1: Baseline Analysis
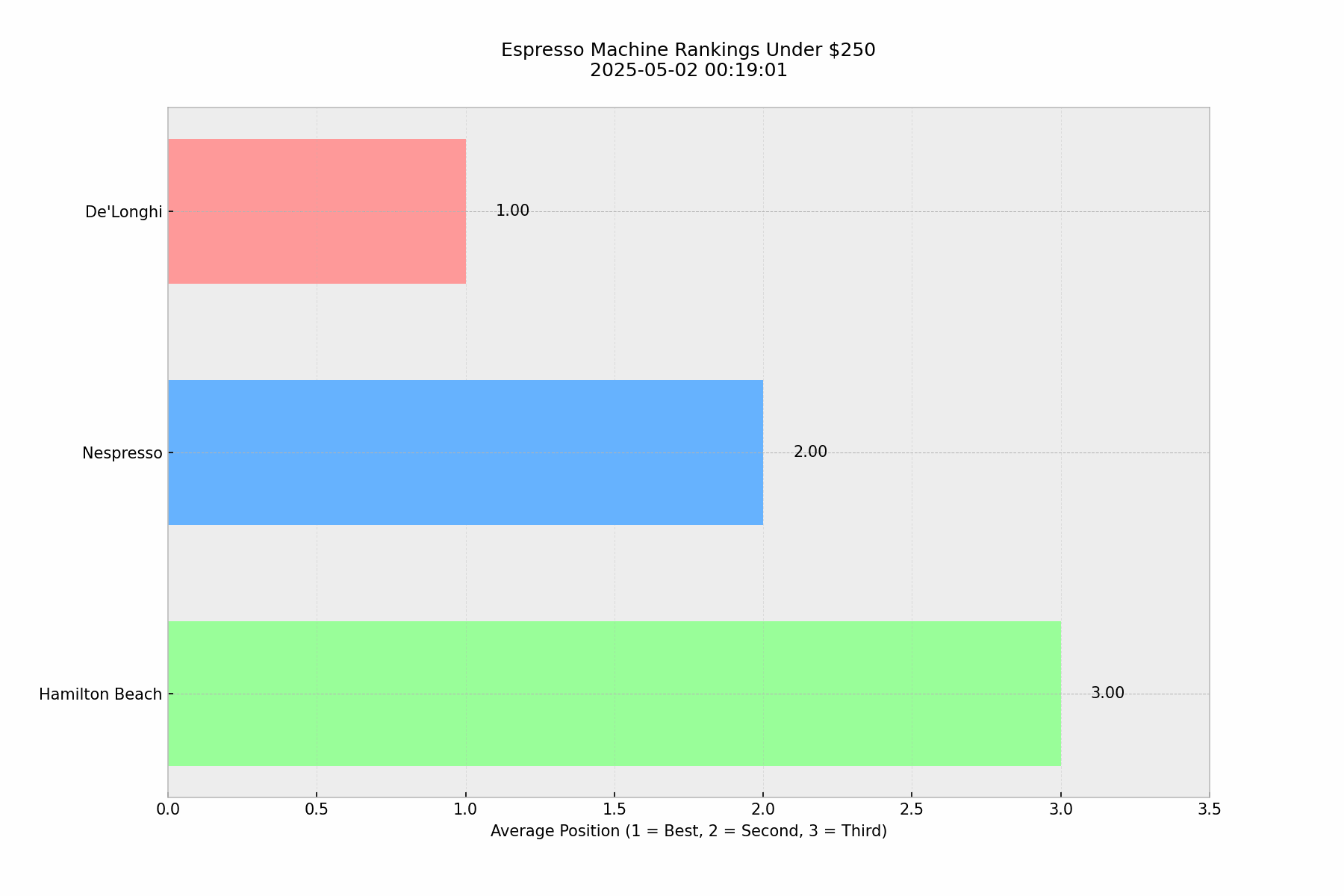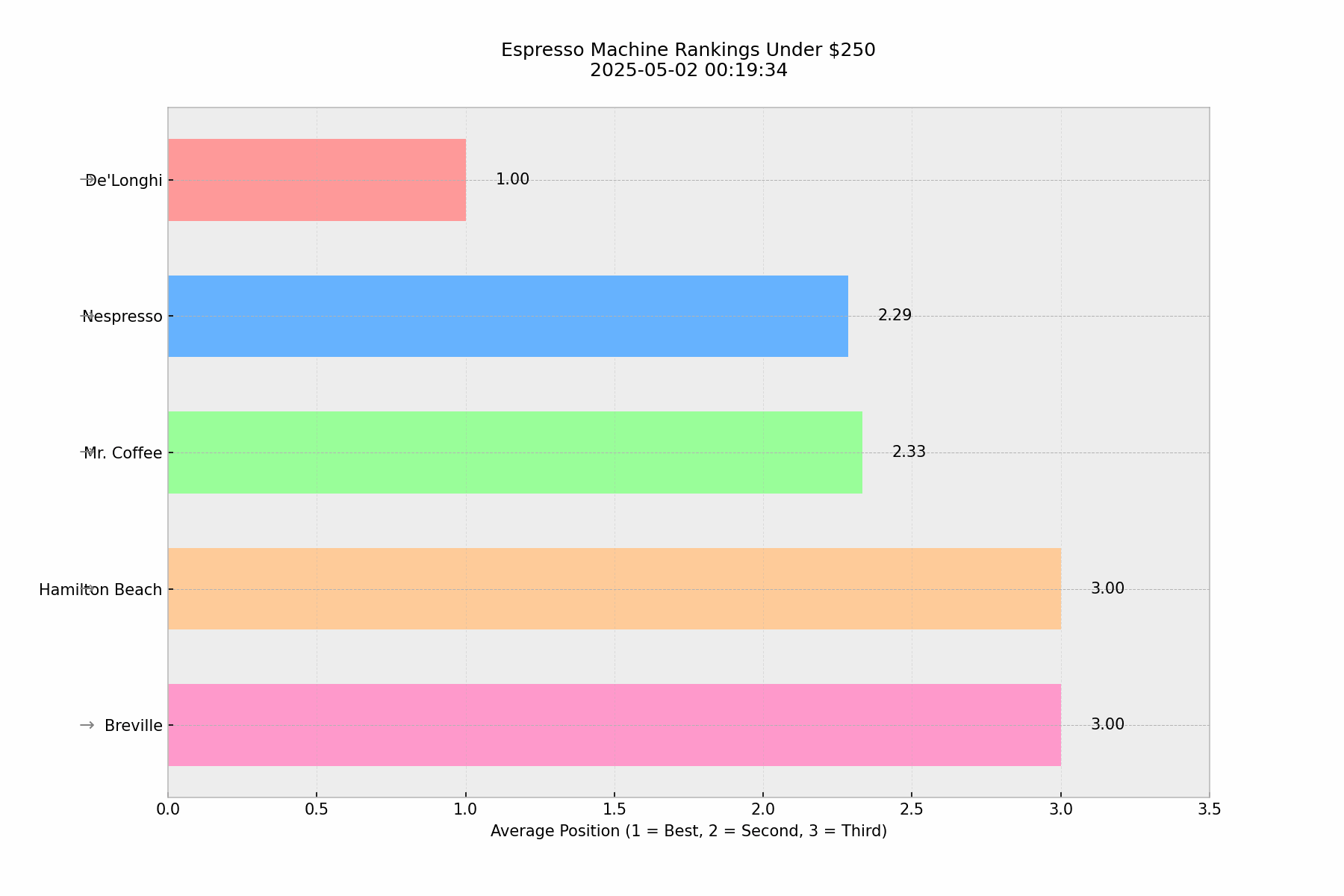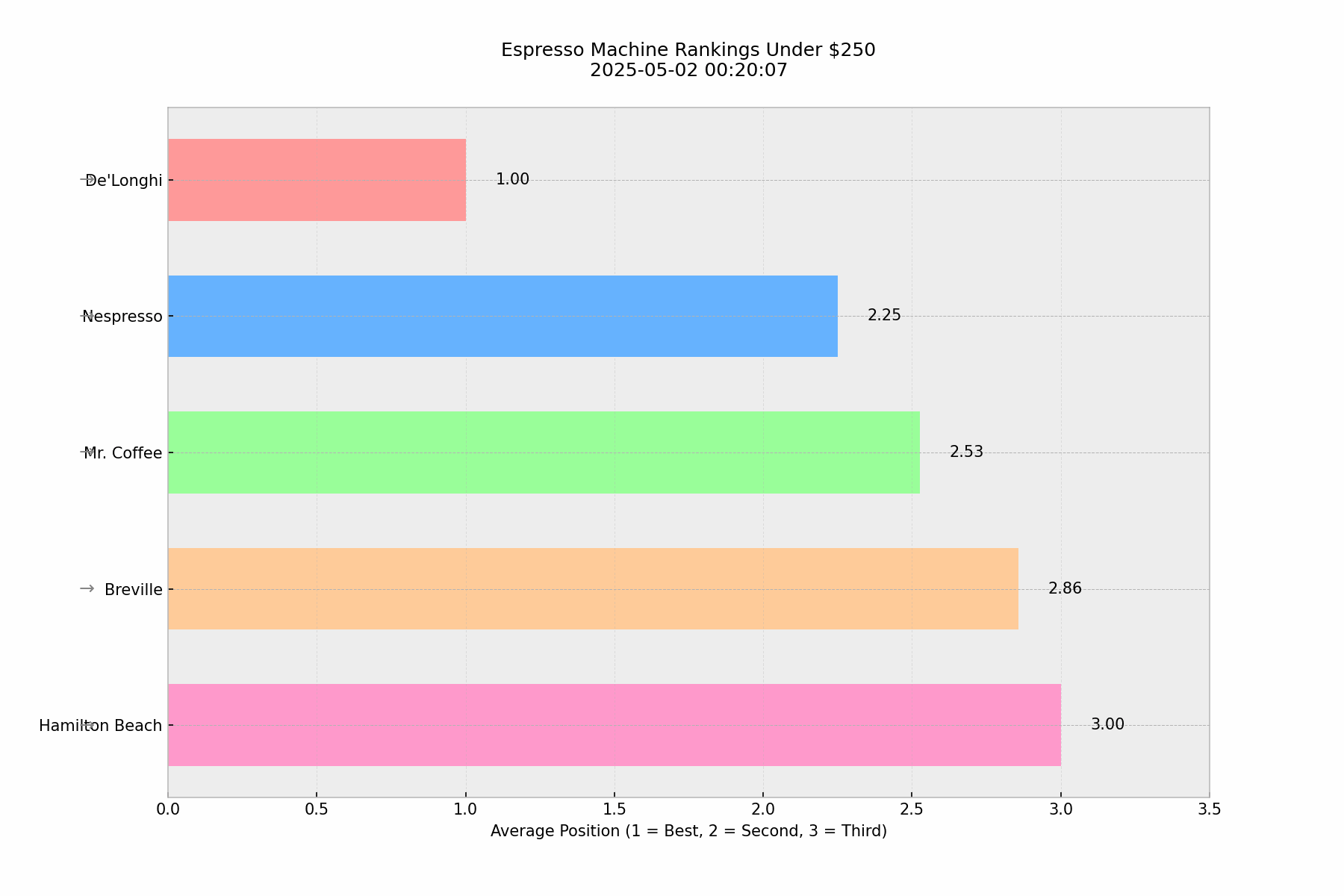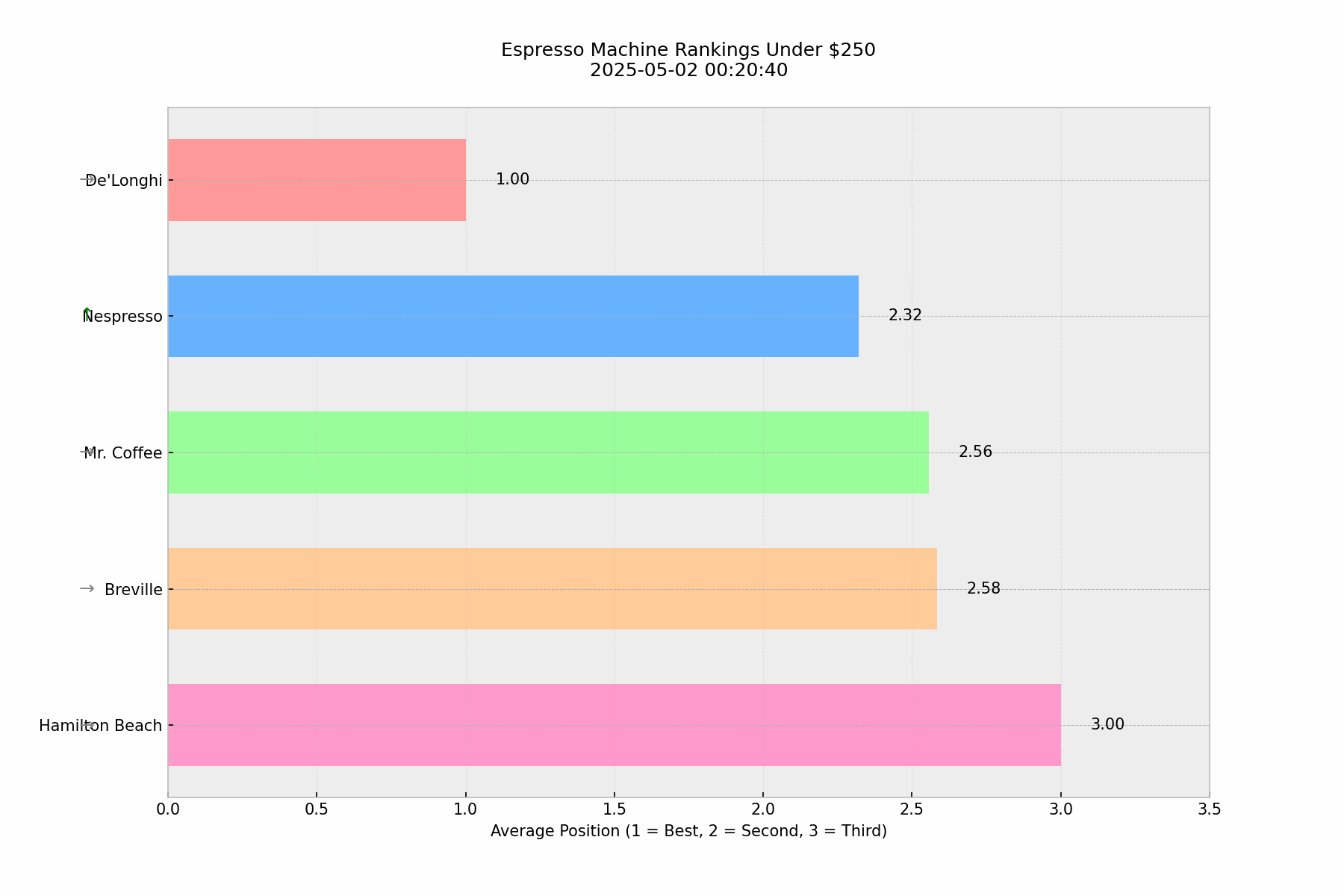
🎯Key Finding: Unexpected Consistency
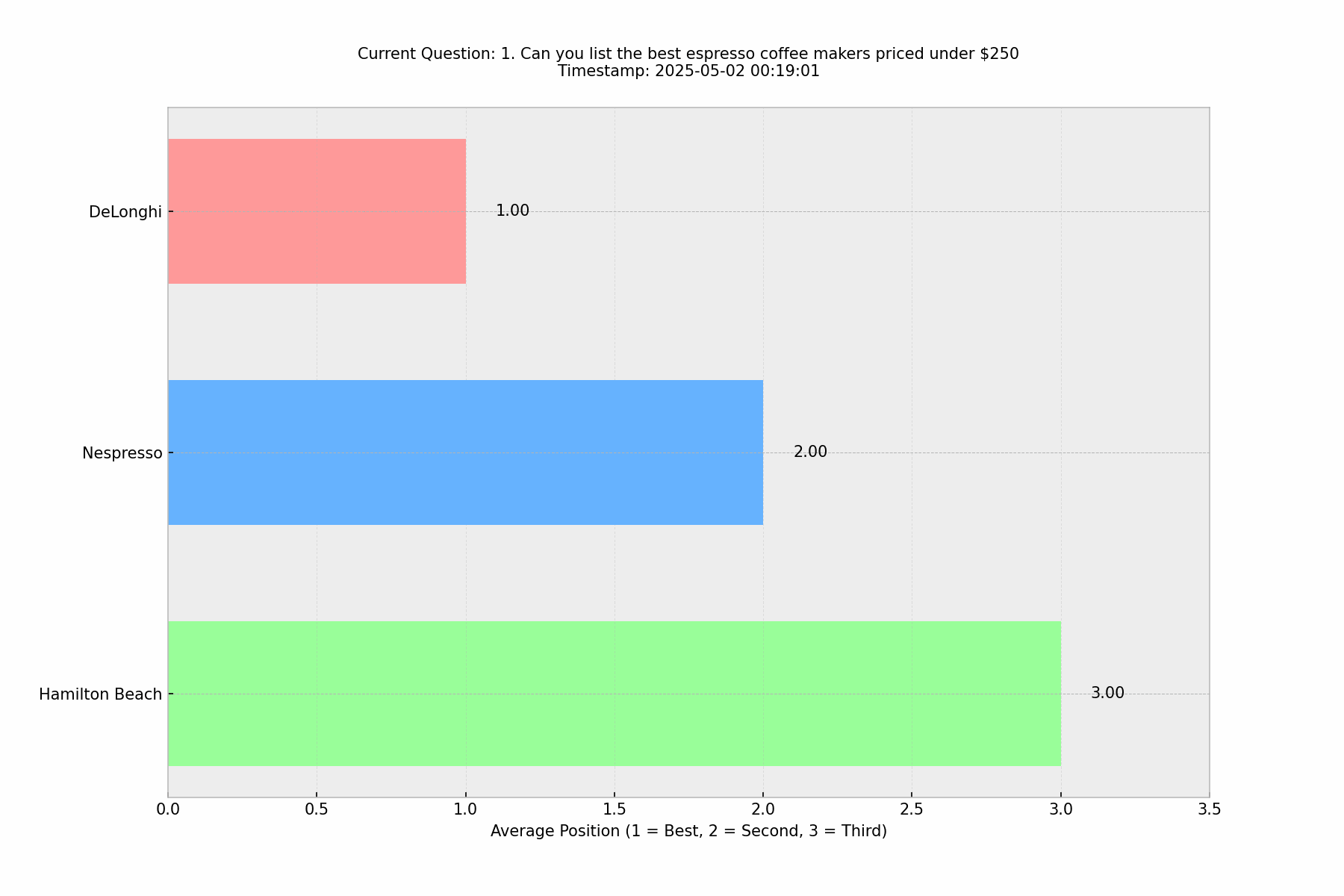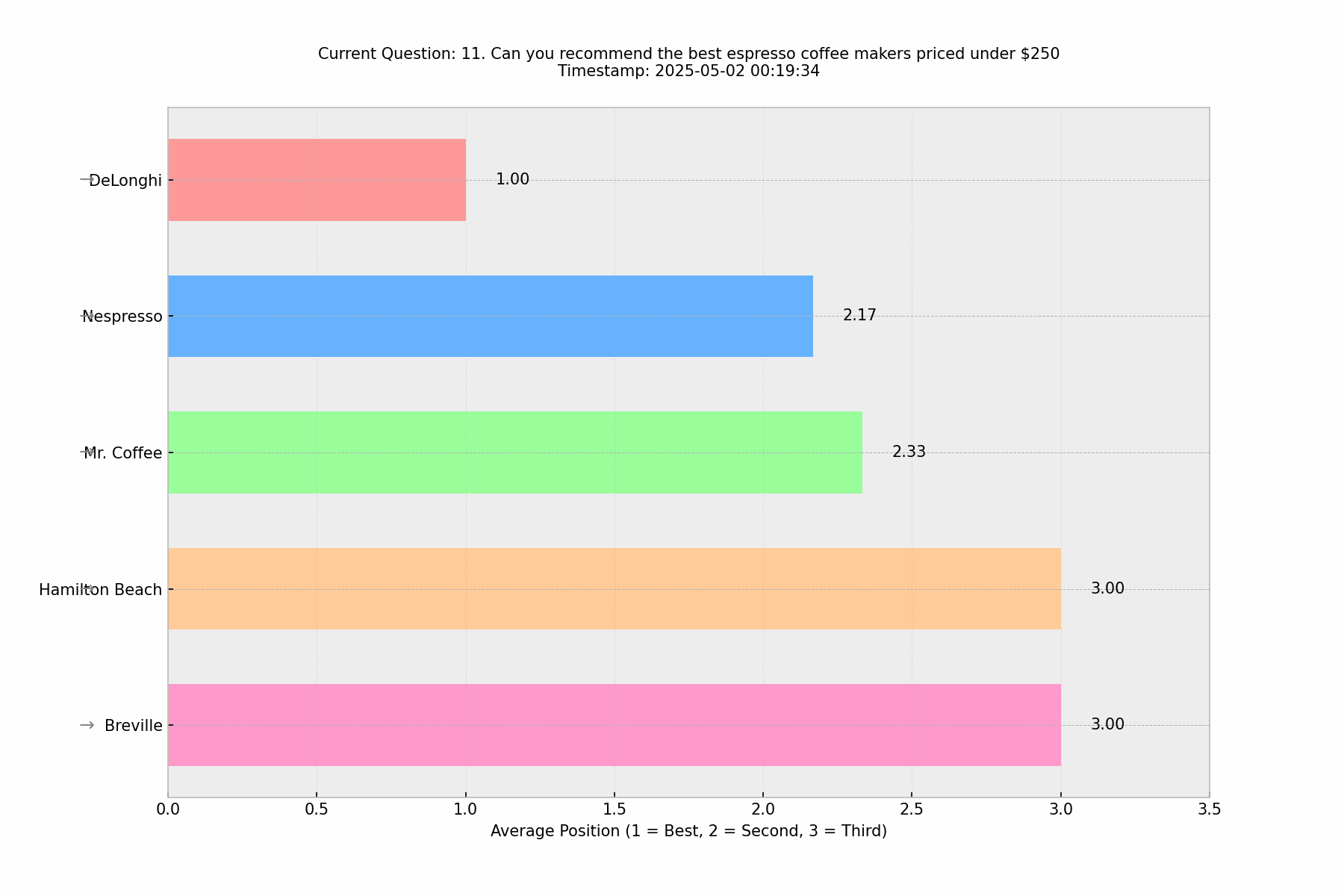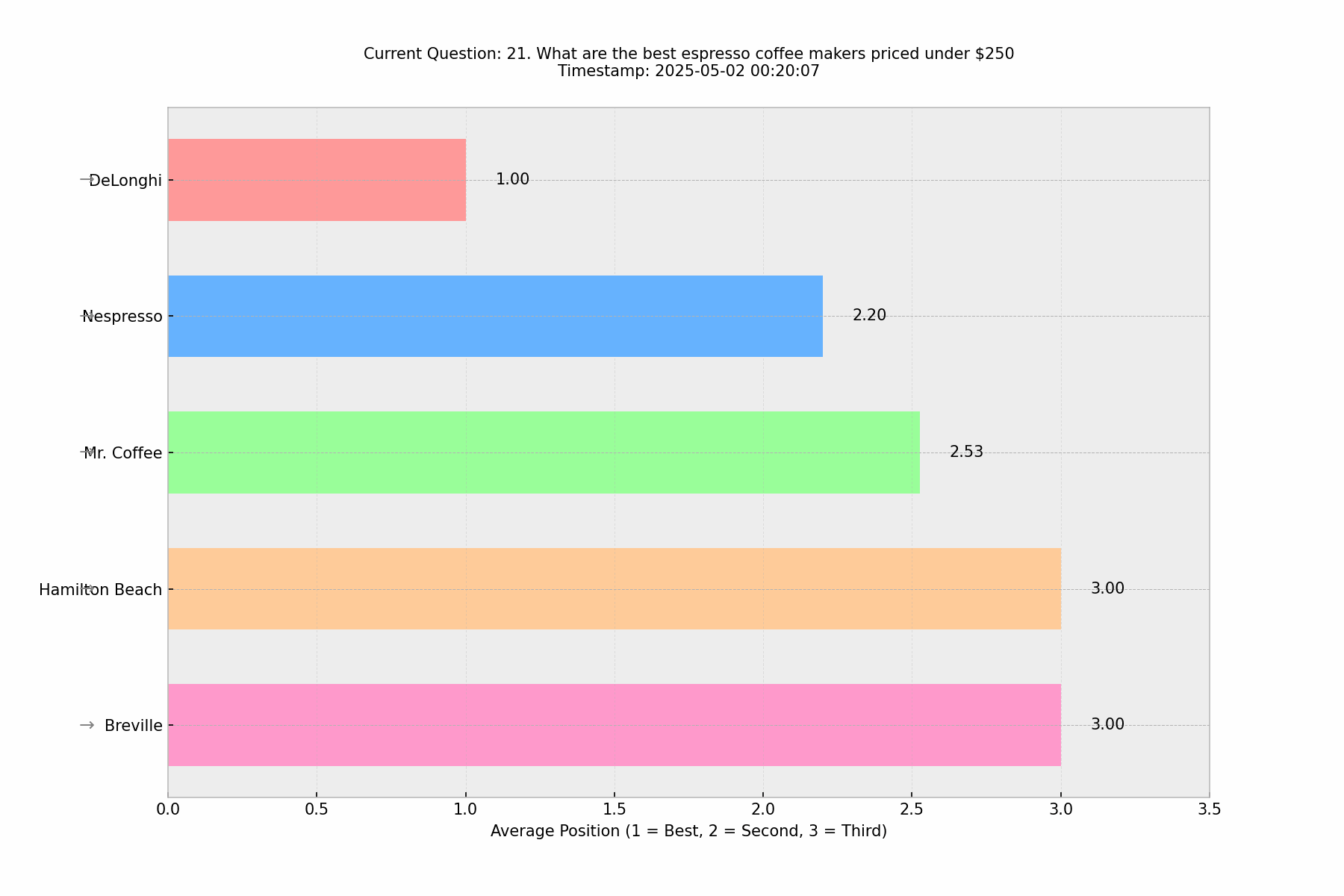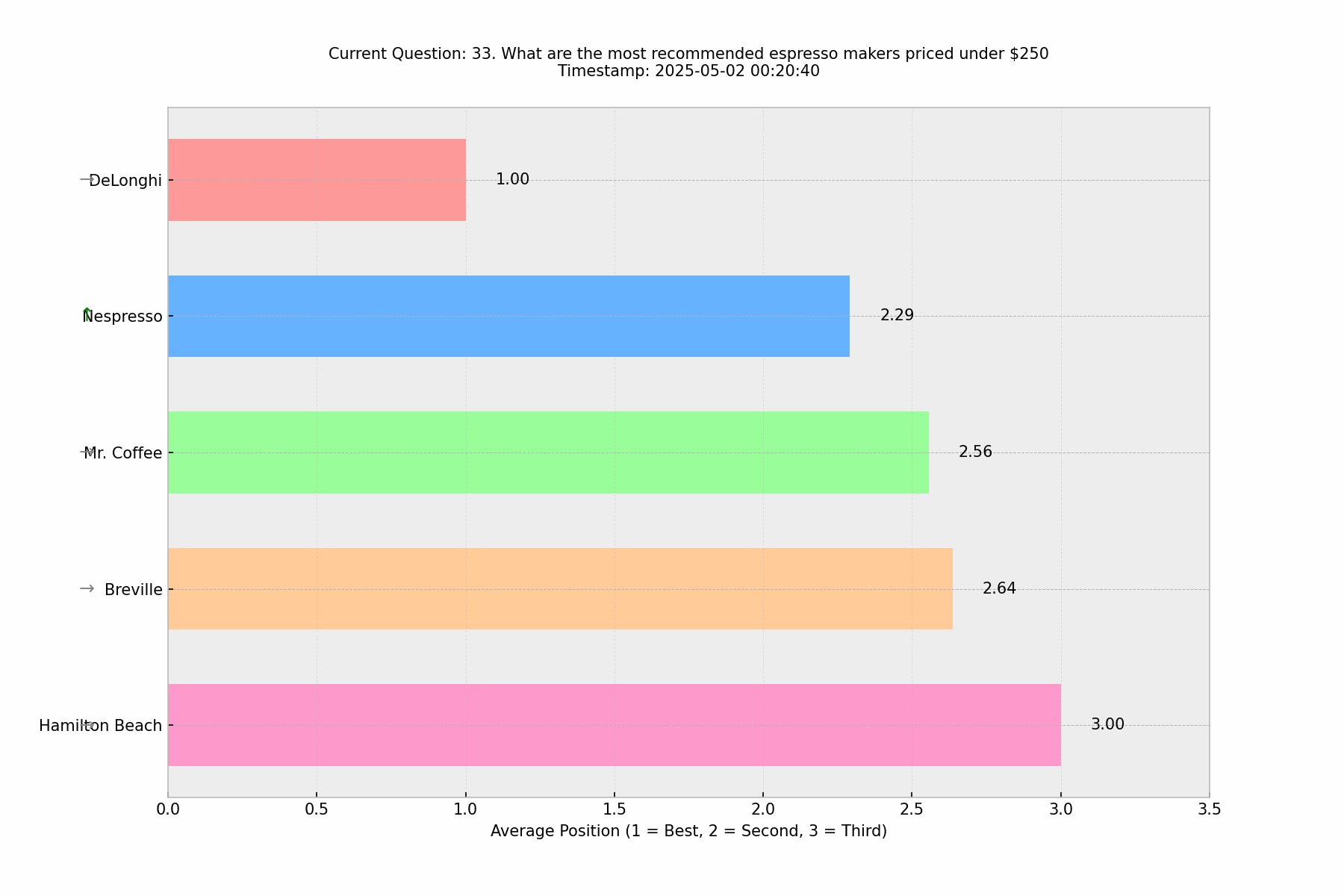
Our baseline analysis of 100 identical queries asking "what's the best espresso machines under $250" revealed a surprising level of consistency in ChatGPT's responses. De'Longhi maintained the #1 position with almost no exceptions, while positions 2–5 showed minor variations in their relative ordering.
This pattern of consistency in top positions, with some flexibility in lower rankings, is actually quite similar to what we observe in Google search results. There were only a few instances (3–4 times) where ChatGPT provided only the top 3 instead of the top 5, but even then, the top 3 remained consistent.
📊Analysis Implications
This finding suggests that ChatGPT does maintain a form of ranking consistency for certain queries, particularly when the question is specific and the product category has clear market leaders. The consistency in De'Longhi's #1 position across 100 runs indicates that ChatGPT's responses aren't entirely random or context-dependent for well-established product categories.
Round 2: Question Variation Analysis
🔄Phrasing Variation Results
In Round 2, we tested Elie Berreby's challenge about question phrasing by introducing subtle variations to the original question. Despite these variations, the results remained remarkably consistent, suggesting that with minor phrasing changes, it's still reasonable to discuss rankings in ChatGPT's responses. The core brands maintained their relative positions, indicating a level of stability in ChatGPT's recommendations for this product category.
Round 2.2: Contextual Variation Analysis
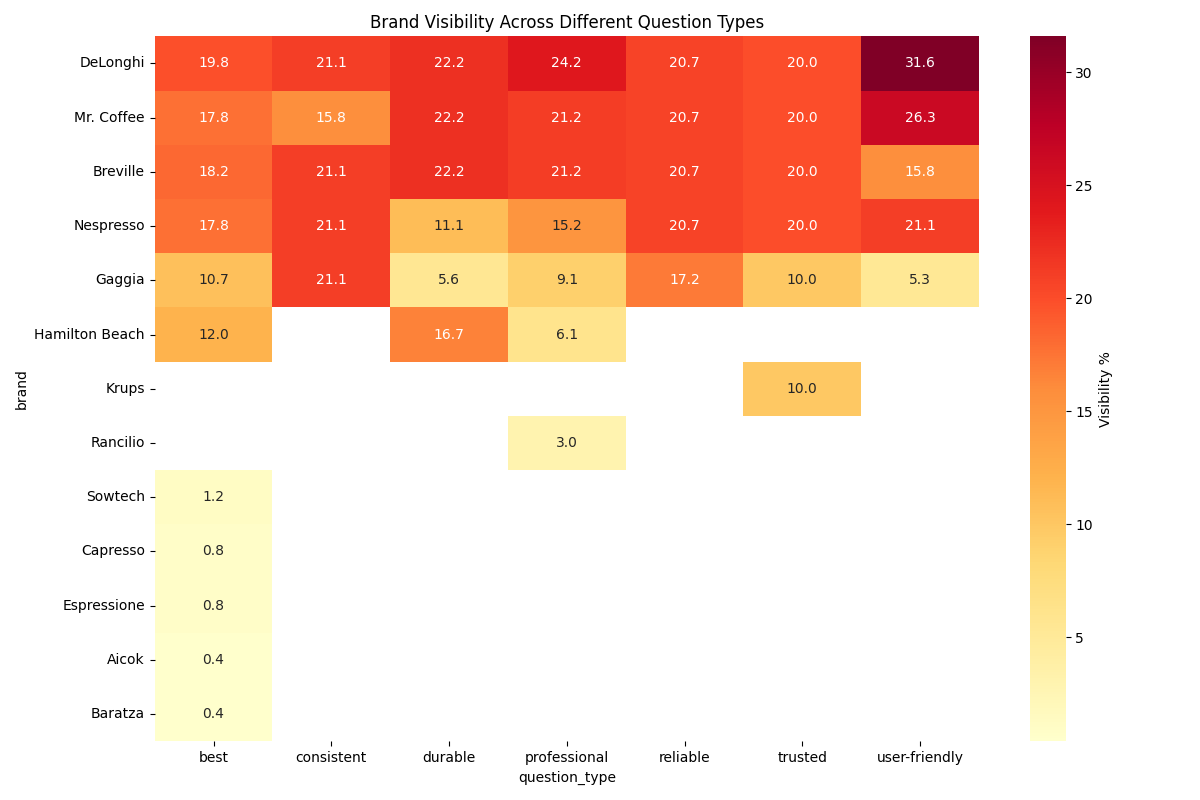
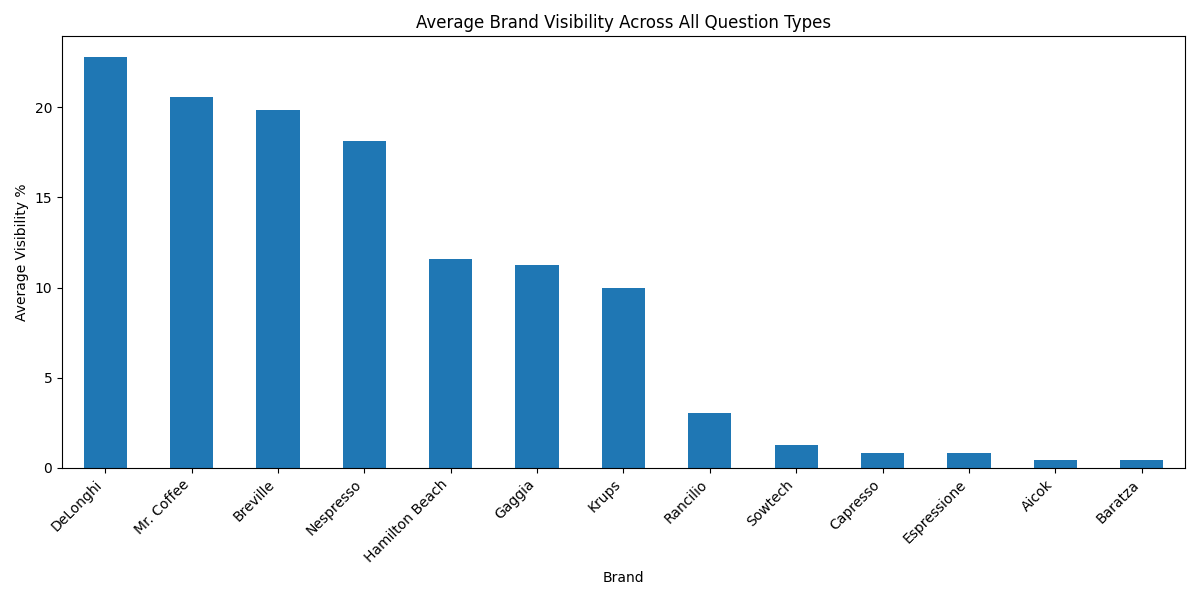
🎨Contextual Impact on Rankings
Round 2.2 introduced stronger contextual variations by incorporating terms like "most reliable," "best taste," and "most professional." This round better aligns with Elie's fundamental challenge about question phrasing, as it demonstrates how different aspects of the same product category can lead to significantly different brand recommendations. While the original brands maintained roughly similar positions, we observed a substantial increase in the total number of distinct brands mentioned.
Round 3: Search Mode Impact
🌐Web Search Integration Effects
Round 3 with search mode enabled revealed how real-time web data affects ChatGPT's brand recommendations. The integration of current web information introduced more variability in responses, suggesting that when ChatGPT has access to recent data, its recommendations become more dynamic and less predictable than the baseline patterns observed in earlier rounds.
Conclusions and Implications
Ranking Consistency
ChatGPT does maintain ranking-like consistency for specific, well-defined product categories with clear market leaders.
Context Sensitivity
Significant contextual changes in queries can dramatically alter brand visibility and recommendation patterns.
Search Mode Impact
Real-time web access increases response variability, making rankings less predictable than baseline models.
Measurement Importance
Understanding AI search patterns requires systematic measurement and analysis rather than assumptions.
🔬Research Takeaways
This experiment challenges both the assumption that AI search lacks rankings and the assumption that it maintains traditional ranking structures. The reality is more nuanced: ChatGPT exhibits ranking-like behavior under certain conditions while showing significant variability in others.